

新闻资讯
在近两小时演讲中,老黄不仅再次上演了一波AI美队,而且还给出了AI时代独一份的洞察——
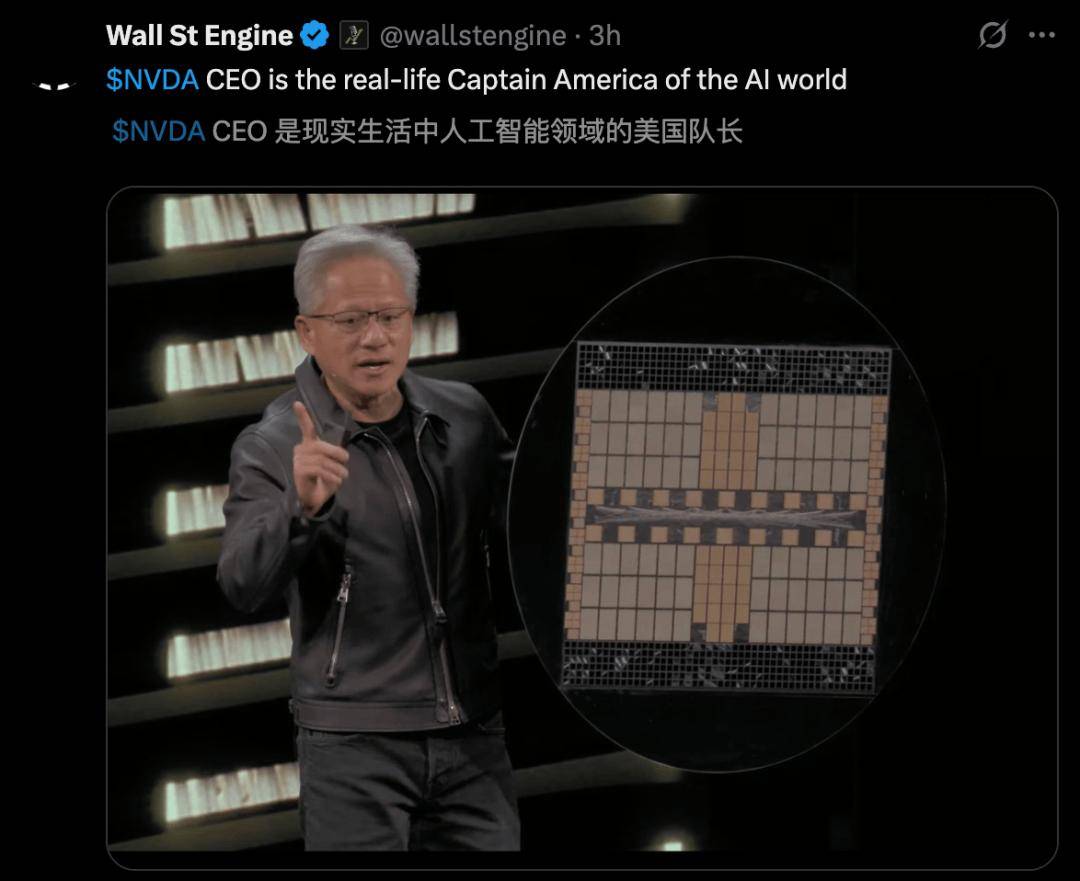
当老黄首次掏出下一代「杀手锏」Vera Rubin超级芯片时,全场都震撼了。
相较于九年前,他亲手交付给OpenAI的首个超算DGX-1,性能足足提升了100倍。并且明年就能量产。

当然,老黄的野心远不止于硬件。接下来的一系列震撼合作,将英伟达的AI帝国展示在了所有人面前:
AI原生6G:推出「AI on RAN」技术,将AI与6G网络深度融合,让基站成为边缘的AI计算中心。
自动驾驶:发布「开箱即用」的DRIVE Hyperion平台,让汽车「生而为Robotaxi」。
量子计算:发布NVQlink技术,首次将AI超算与量子处理器无缝连接,加速量子计算的实用化进程。
物理AI:通过Omniverse中的数字孪生技术,训练「物理AI」,加速机器人在现实世界中的部署,目标直指美国「再工业化」。
老黄预测,在2026年底前,仅凭「Blackwell+Rubin」就足以冲击5000亿美元的营收。
现场,老黄再次搬出了,未来三年英伟达GPU路线图,从Blackwell,到Rubin,再到Feynman。

他激动官宣,短短9个月后,Blackwell芯片已在亚利桑那州全面量产。
这是英伟达第三代NVlink 72机架级超级计算机,彻底实现了无线缆连接。
目前,Vera Rubin超级芯片已在实验室完成测试,预计明年10月可以投产。


同时,英伟达还引入了一种全新「上下文处理器」(Context Processor),支持超100万token上下文。
如今,AI模型要处理、记忆的上下文越来越多,它可以在回答问题前,学习和阅读成千上万份PDF、论文、视频。


还有NVlink交换机,可以让所有GPU同步传输数据;以太网交换机Spectrum-X可以确保处理器同时通信而不拥堵。


它的主干网络,一秒内就能传输相当于整个互联网的流量,刷新全球最快的token生成速度。
老黄表示,「一个1GW规模的数据中心,大概需要8000-9000台这样的机架。这就是未来的AI工厂」!
他将其比作一个数据密集型的「编程」,在CPU时代的旧世界,人们手工编码,软件在CPU上运行,Windows主导了一切。
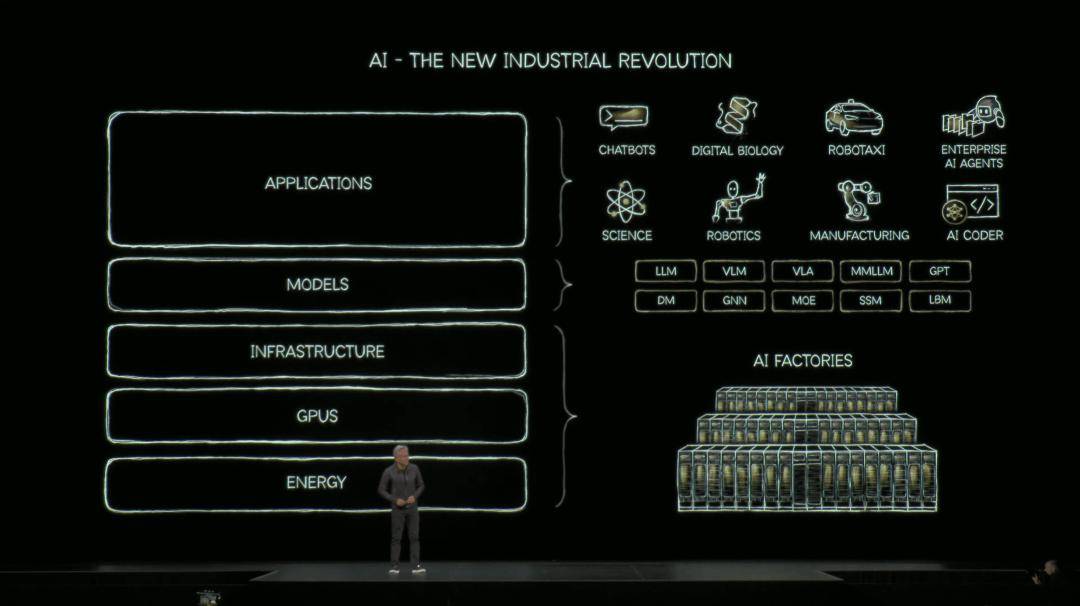
过去的软件产业,本质上是在「造工具」,Excel、Word、浏览器皆是工具。
在IT领域,这些工具可能就是「数据库」之类的,其市场规模大约在一万亿美元左右。
老黄举例道,英伟达每一位工程师都在用Cursor,生产力得以大幅提升。而Cursor使用的工具是VS Code。
AI本身也正在成为一个「全新的产业」,当人们把各种形式的信息编程token之后,就需要一个「AI工厂」。
「AI工厂」不同于过去的数据中心,是因为它基本上只做一件事——运行AI。
一来,生产尽可能有价值、更智能的token;其次,要用极高的速度将其生产出来。
下一步就是后训练,再之后就是测试时,让AI不断思考(Long Thinking)。
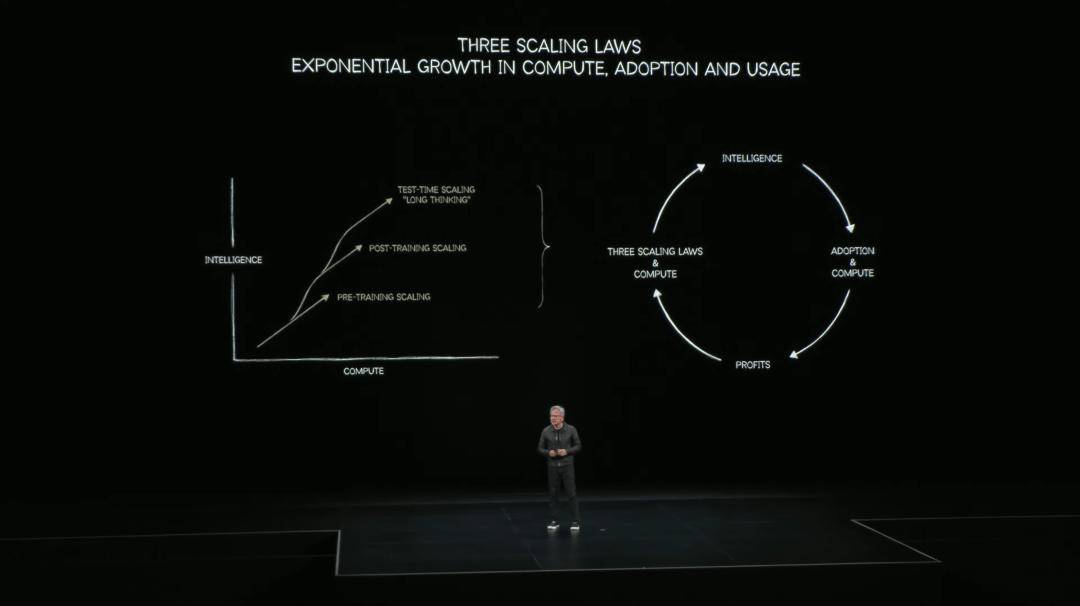
与此同时,摩尔定律边际趋缓,仅靠狂堆晶体管,无法解决两条指数曲线带来的「饥饿感」。
英伟达是当今世界上,唯一一家真正从一张白纸开始,同时思考芯片、系统、软件、模型、应用的公司。
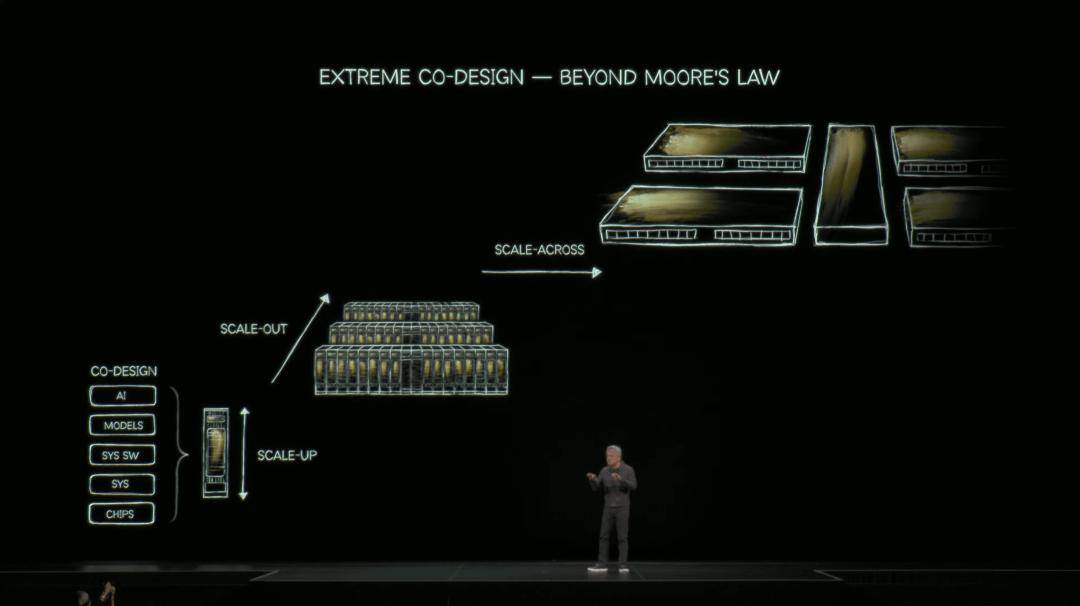
Grace Blackwell NVL72,一台思考机器,就是英伟达「协同设计」的典型代表。

为了更直观说明,老黄再次上演「芯片版美队」,手里拿着巨型芯片,由72块GPU无缝互联。

为了驾驭万亿级参数模型,它采用了MoE架构。传统系统受限于GPU间互联带宽,一块GPU要扛32位专家的计算。


老黄展示了,全球六大云巨头的资本支出曲线(CapEx),正以史无前例的速度飙升。
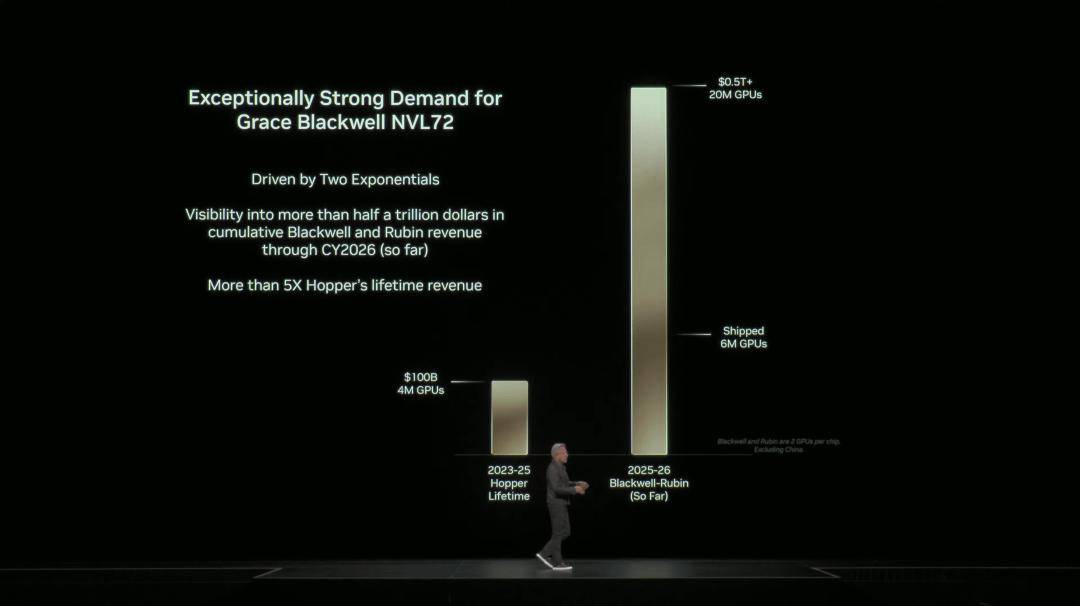
最令人震惊是,他预测,截至2026年,Blackwell+Rubin的可预见性收入累计5000亿美元。
算上目前已经出货的600万块Blackwell,未来两年将达2000万GPU出货量,相较于Hopper增长5倍(400万块)。
不仅如此,老黄这场演讲,还在向世界宣告:英伟达不仅是算力之王,更是AI生态的绝对核心。
老黄一针见血,「过去几年,开源AI在推理、多模态、蒸馏效率三大维度上,实现巨大飞跃」。
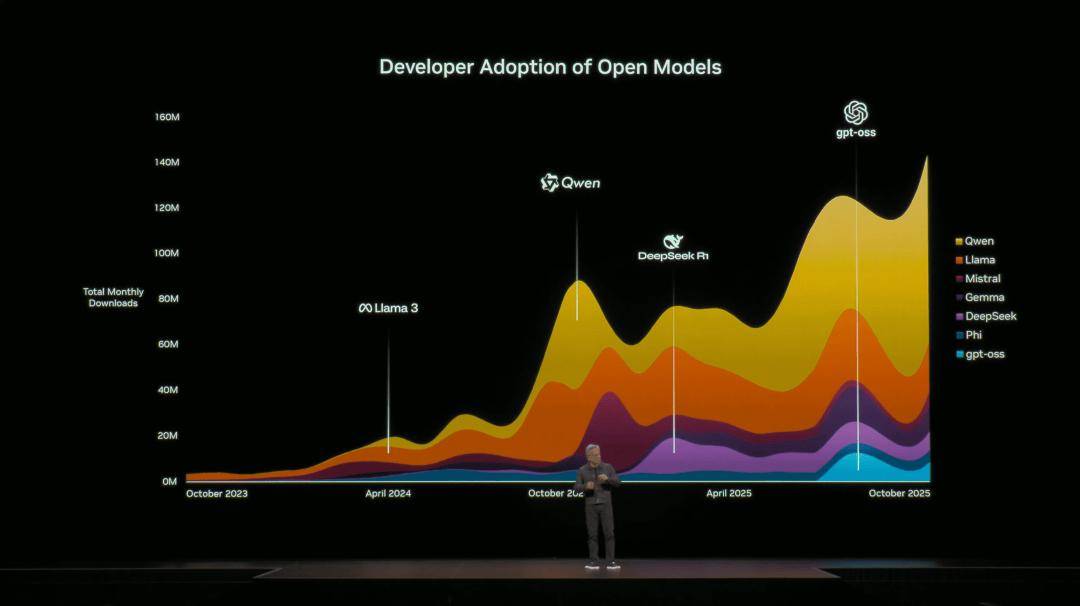
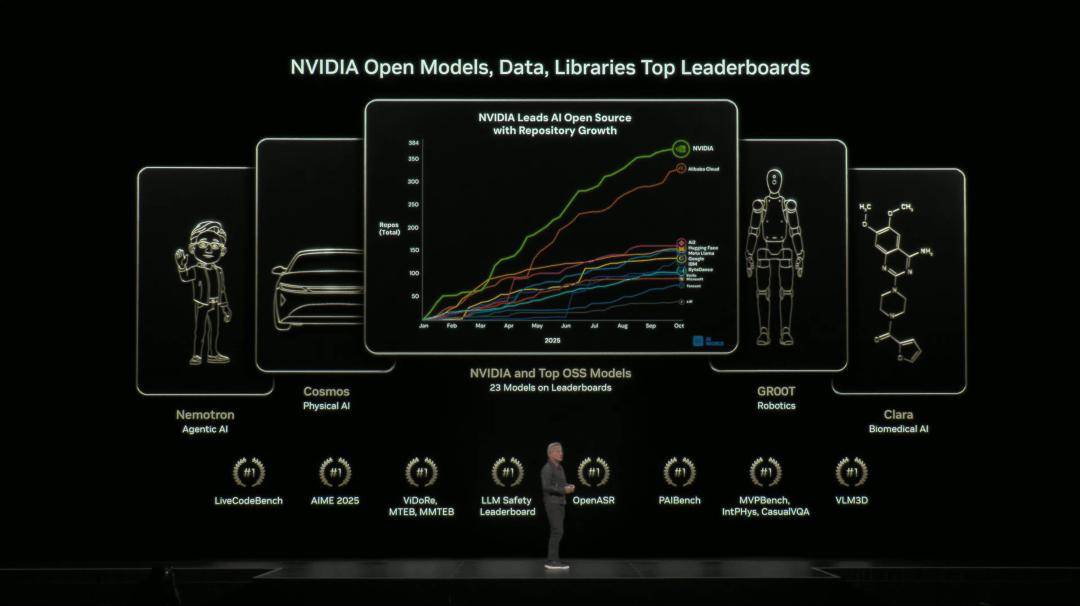
为此,英伟达也在全力投入这一方向。目前,他们在全球开源贡献榜上,23个模型上榜,覆盖了语言、物理AI、语音、推理等全领域。
我们拥有全球第一的语音模型、第一的推理模型、第一的物理AI模型。下载量也非常惊人。
一个是GPU超算用于训练,一个通过Omniverse Computer用于模拟,另一个是机器人计算机。
以上这三种计算机上都运行着CUDA,由此才能推动「物理AI」发展,也就是理解物理世界、物理定律、因果关系的AI。

目前,英伟达正联手伙伴,打造一个工厂级的物理AI。一旦建成,就会有大量机器人在数字孪生的世界中工作。
在自动驾驶领域,英伟达推出了一套「开箱即用的L4级自动驾驶底座」——DRIVE AGX Hyperion 10。
它搭载了NVIDIA DRIVE AGX Thor系统级芯片、经过安全认证的NVIDIA DriveOS操作系统、一套经过完整认证的多模态传感器套件(包含14个高清摄像头、9个雷达、1个激光雷达和12个超声波传感器)以及认证的板卡设计。
迭代与验证:平台可OTA升级、兼容现有AV软件,并引入Foretellix Foretify Physical AI工具链做测试与验证;同时开放全球最大多模态AV数据集(1700小时、25国),用于基础模型的开发/后训练/验证。
在数万亿英里真实及合成驾驶数据的加持下,新一代VLA(视觉-语言-动作)推理模型,让车辆不只能识别红绿灯,还能在无结构路口或人车行为突变时做出类人判断(比如理解交警临时指挥、突发改道),而且是在车上实时完成。
对于行业来说,公司可以直接拿到可量产的参考架构与数据/验证闭环,更快把Robotaxi或无人配送车跑起来。

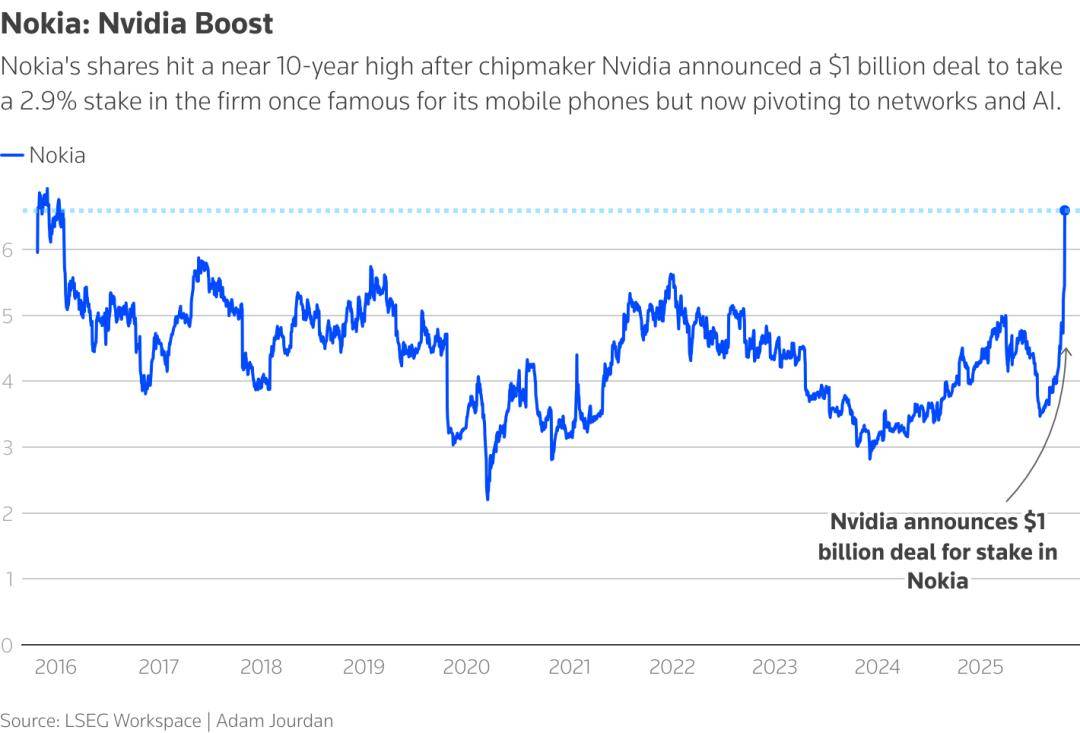
在通信行业,英伟达则宣布与诺基亚达成合作,并推出了支持AI原生6G的加速计算平台——Aerial RAN Computer Pro(ARC-Pro)。
ARC-Pro = AI基站主机:融合了「连接+计算+感知」能力的6G-ready加速计算平台;运营商未来可以通过软件升级的方式从5G-Advanced升到6G。
AI-RAN = 无线+AI共生:把AI推理(如频谱调度、节能控制、用户体验优化)和传统RAN处理跑在同一套、由GPU加速的软定义基础设施上;同一站点还能顺带承载生成式/智能体AI的边缘服务,有效利用「基站闲时算力」。

交易宣布后,诺基亚股价收盘上涨20.86%,创下自2016年1月下旬以来的新高。
在量子计算领域,众所周知,量子计算机的核心「量子比特」(Qubits),虽具备碾压传统计算机的并行计算潜力,但在计算过程会不断产生错误。
为了让它们正常工作,就必须依赖一台传统的超级计算机,通过一条要求严苛的超低延迟、超高吞吐量的连接,实时进行复杂的校准和纠错。

为此,英伟达推出了一款全新的互连技术——NVQlink,首次将量子处理器与AI超级计算机无缝地、紧密地连接在一起,形成一个单一、连贯的超级系统。
硬件层:通过NVQlink,研究人员可以把不同量子路线(超导、离子阱、光子等)的处理器和控制硬件直接接到GPU超算上,避免了「绕以太网一大圈」的抖动与时延;同时,连在一起的GPU集群还可以继续向外扩展。
软件层:通过CUDA-Q,研究人员可以在同一套编程接口里,把CPU、GPU、QPU编排成一台「混合超算」,让仿真、编排、实时控制能够在一个平台里闭环。
生态层:集合9家美国实验室、17家量子硬件公司、5家控制系统公司之力,目标是把校准、纠错、混合应用做成可复用的「套路」。
正如老黄所说:「NVQlink是连接量子和经典超级计算机的罗塞塔石碑。它的出现,标志着量子-GPU计算时代的正式开启。」
